你可能听说过 Quantum 项目…… 它是 Firefox 内部组件的重大改写,为了让 Firefox 更快。 开发者对测试版浏览器 Servo 做组件替换,同时对引擎的其它部分进行改进。
这一项目就像给正在飞行的喷气式飞机更换发动机。 开发者逐个组件做适当修改,一旦某个组件完成,马上可以看到效果。
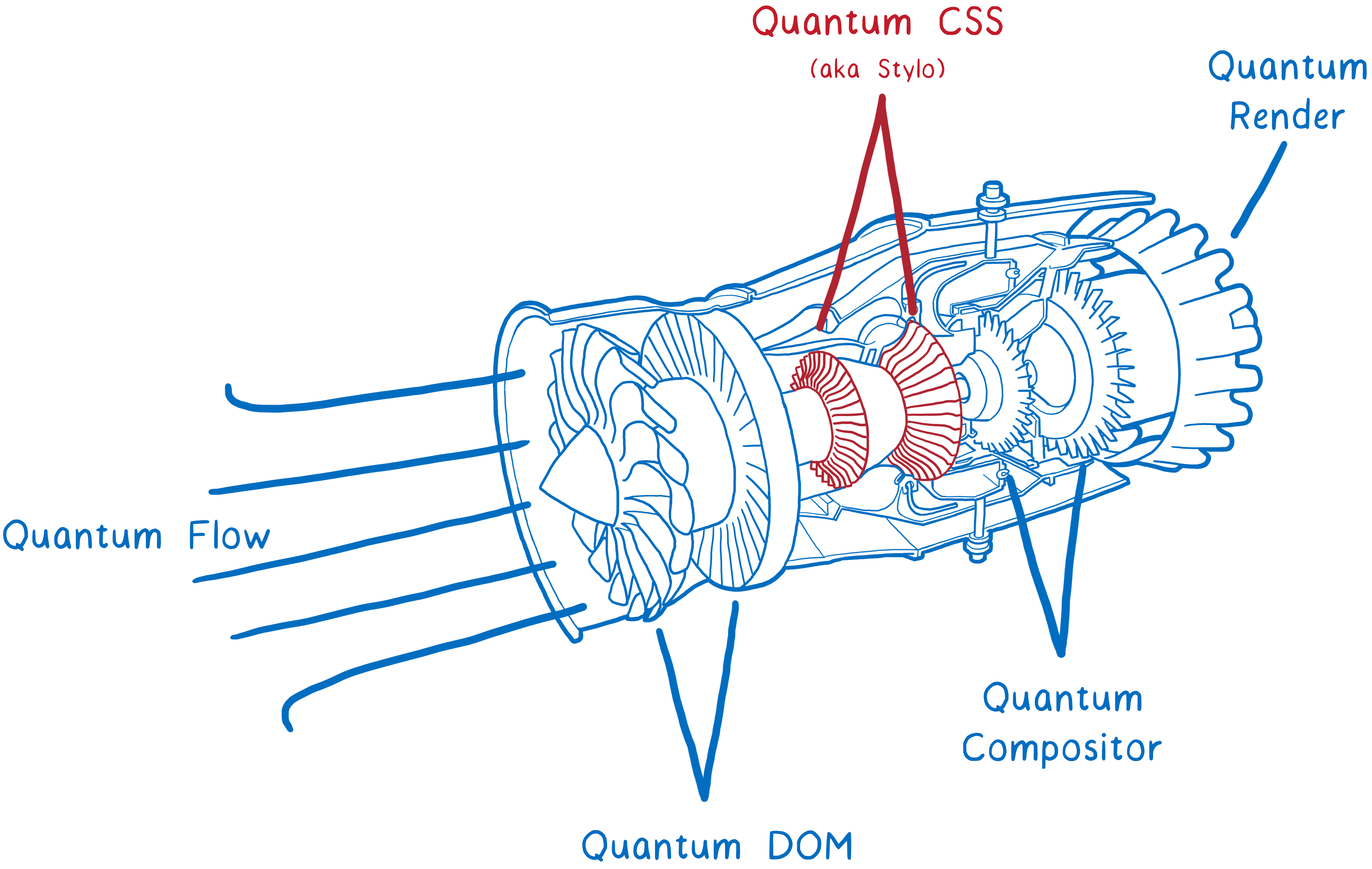
Servo 的第一个主要组件——Quantum CSS 引擎(曾经叫做 Stylo)——已经在每日构建版本中测试。
要确保该功能打开,可以进入 about:config,设置 layout.css.servo.enabled 为 true。
这一引擎吸收了四种浏览器的最先进创新技术,创建了新的超级 CSS 引擎。
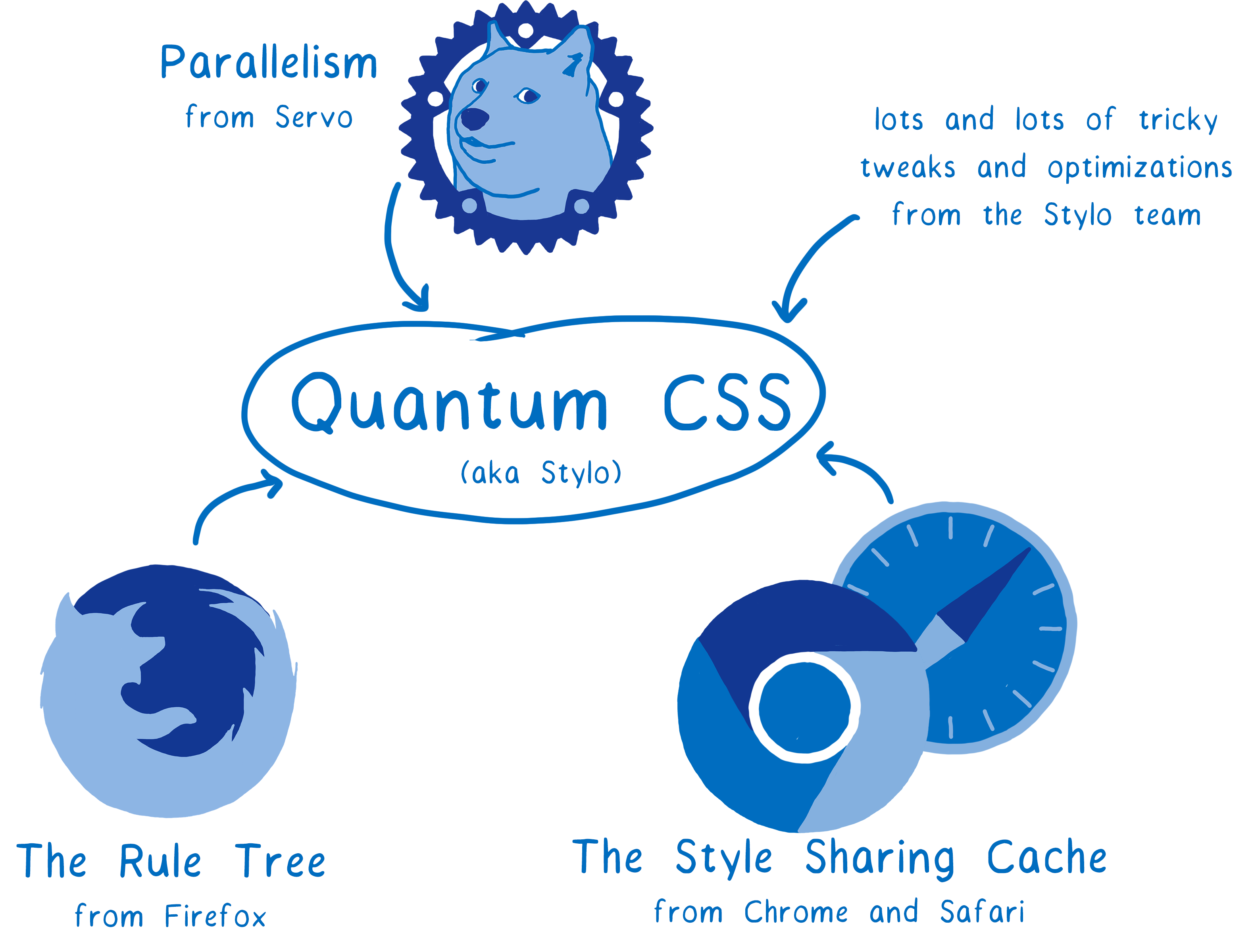
它充分利用现代化硬件的优势,在机器的全部核心上并行化执行工作任务。 这意味着它能以 2 倍 或者 4倍 甚至 18 倍的速度运行。
更重要的是,它结合了来自其它浏览器的优化方案。 即使没有并行化执行,也会是一个快速的 CSS 引擎。

那么,什么是 CSS 引擎呢? 首先来了解 CSS 引擎, 它如何与浏览器的其余部分配合。 然后再看看 Quantum CSS 如何实现速度更快。
CSS 引擎做什么?
CSS 引擎是浏览器渲染引擎的一部分。 渲染引擎获取网站的 HTML 和 CSS 文件,并将其转换为屏幕上的像素。

每个浏览器都有渲染引擎。 Chrome 中叫作 Blink。 Edge 中叫作 EdgeHTML。 Safari 中叫作 WebKit。 而 Firefox 中叫作 Gecko。
从文件转换为像素,所有渲染引擎在做基本类似的事情:
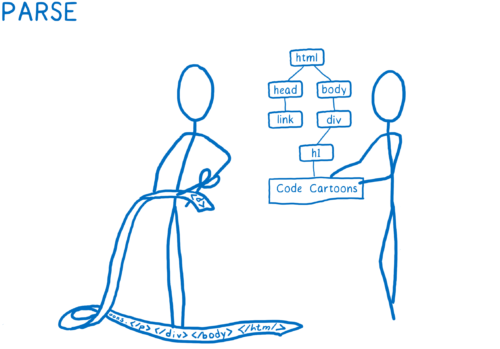
- 将文件解析为浏览器可以理解的对象,包括 DOM。
在这一步,DOM 获知页面的结构。
它知道元素之间的父/子关系。
却并不知道这些元素如何显示。
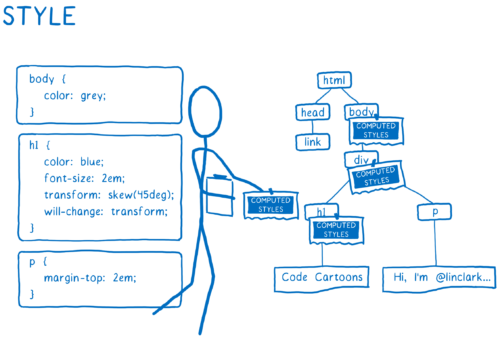
- 计算出这些元素的样子。
对每一个 DOM 节点,CSS 引擎先确定适用哪个 CSS 规则。
然后计算该节点的每个 CSS 属性的值。
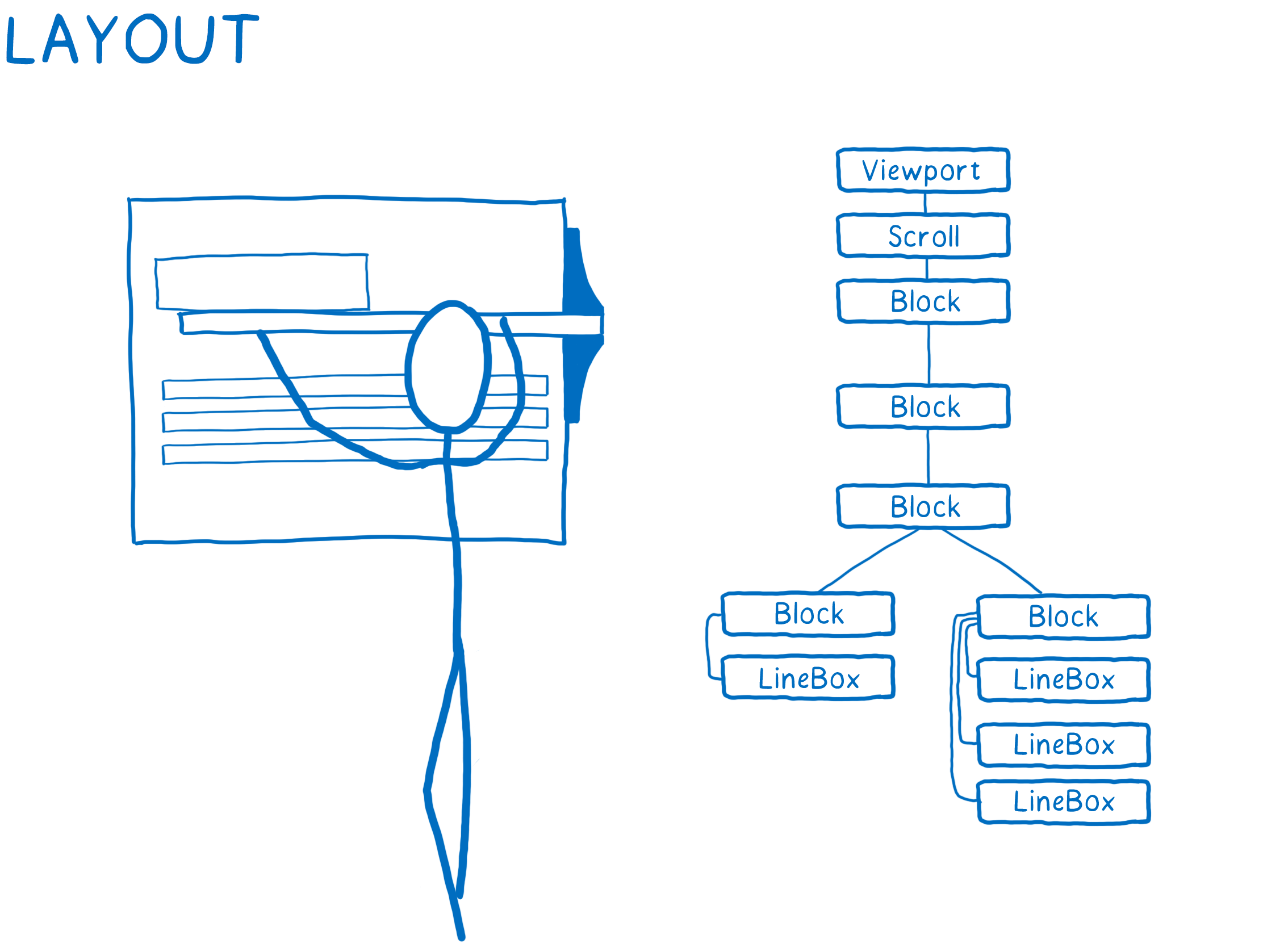
- 确定每个节点的尺寸及其在屏幕上的位置。
为每个即将显示在屏幕上的目标创建盒子。
盒子不只可以代表 DOM 节点…… 也可以是 DOM 节点内部的文本行。
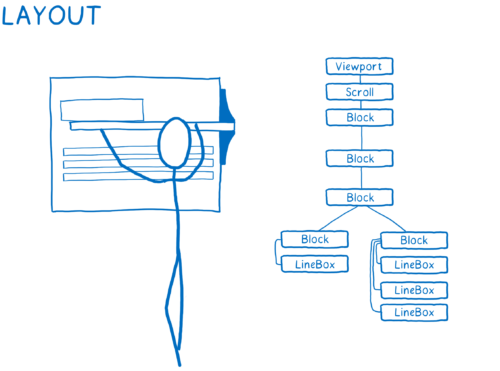
- 绘制出不同的盒子。
可能是在多个层上进行绘制。
这就像过去的手绘动画,用的是半透明薄纸层。
如果需要,可以只修改一个层,而不必重绘其它层的东西。
- 对这些图层,应用合并操作(如变形),并将它们转化为图像。
就像给叠起来的图层拍摄照片一样。
图像将在屏幕上呈现。


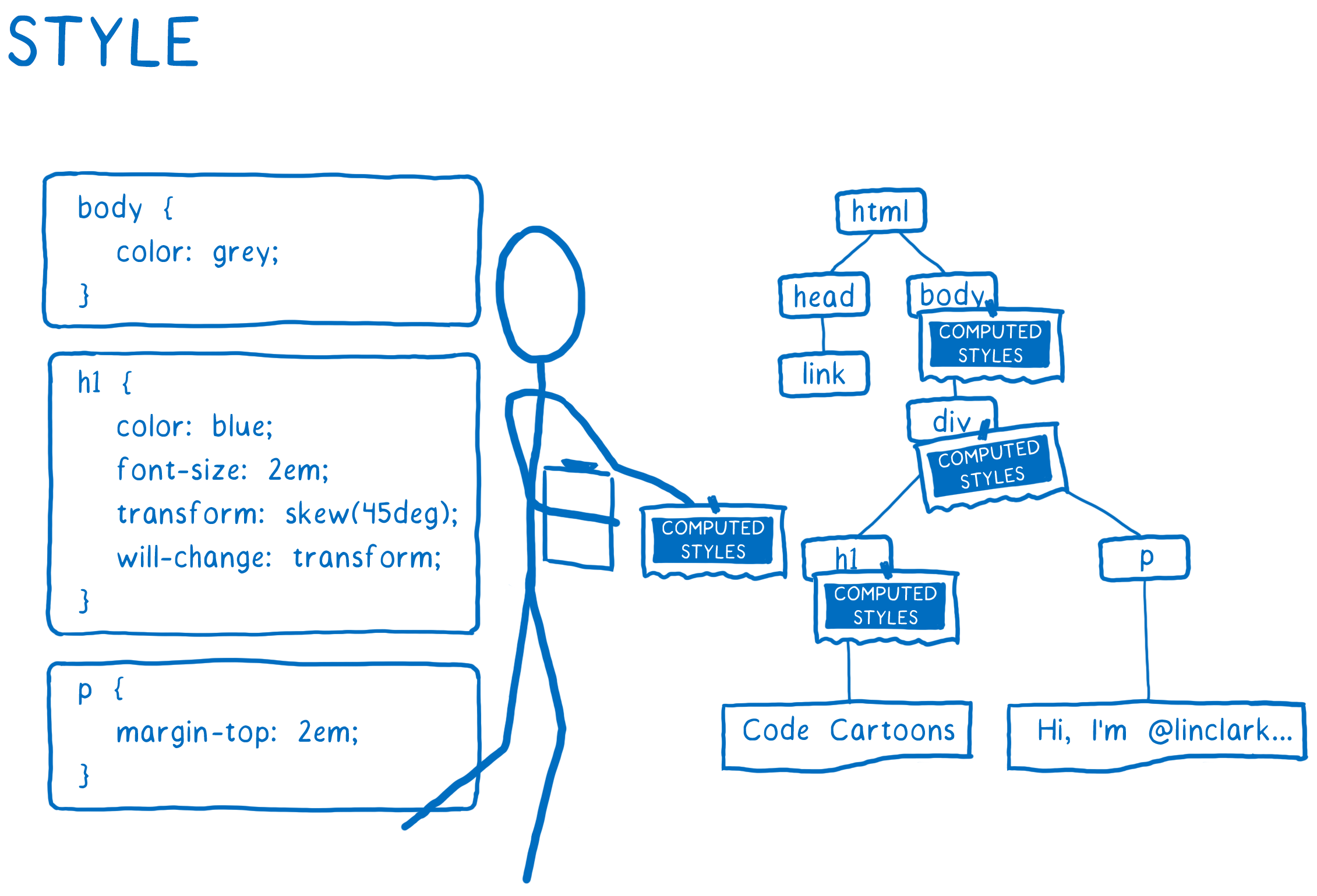

也就是说,当开始计算样式时,CSS 引擎做两件事:
- DOM 树
- 样式规则列表
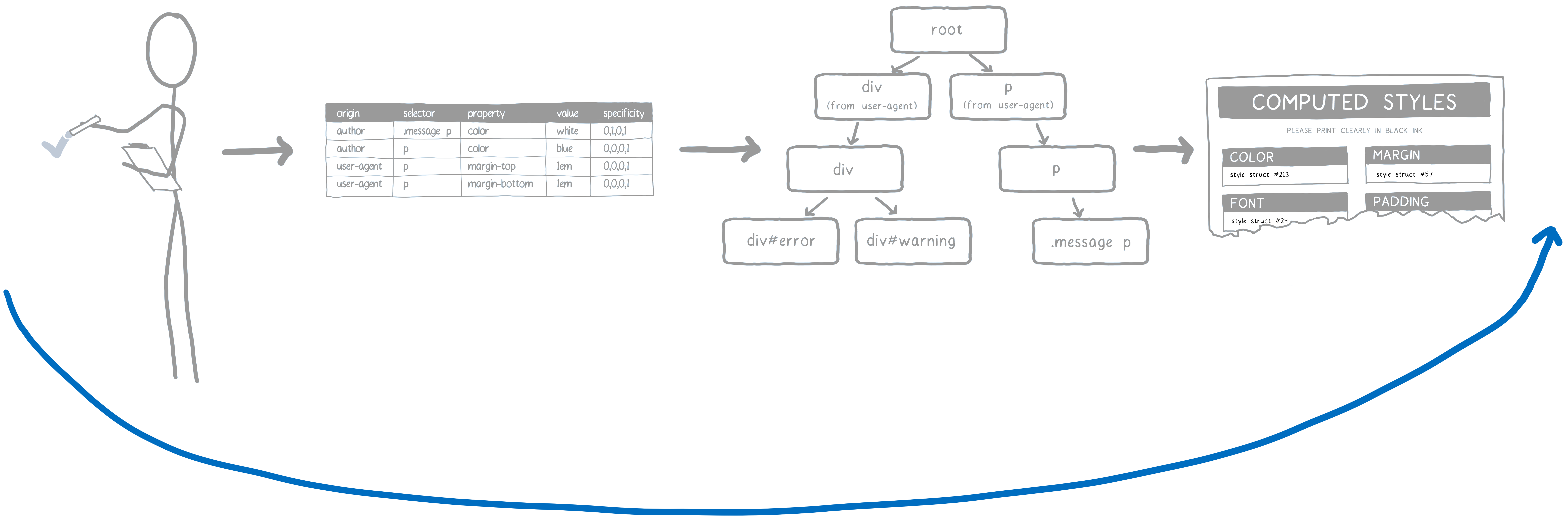
它逐个遍历每个 DOM 节点,计算该节点的样式。 并给出 DOM 节点每个/全部属性的值,即使样式表没有声明该属性的值。
就像在填写表格。 为每个 DOM 节点填写一份这样的表格。 表格的每个字段都需要填写一个答案。

要实现这一点,CSS 引擎需要做两件事:
- 确定哪些规则适用于节点 —— 通过 选择器匹配
- 使用父节点或默认值填充缺失的值 —— 通过 层叠
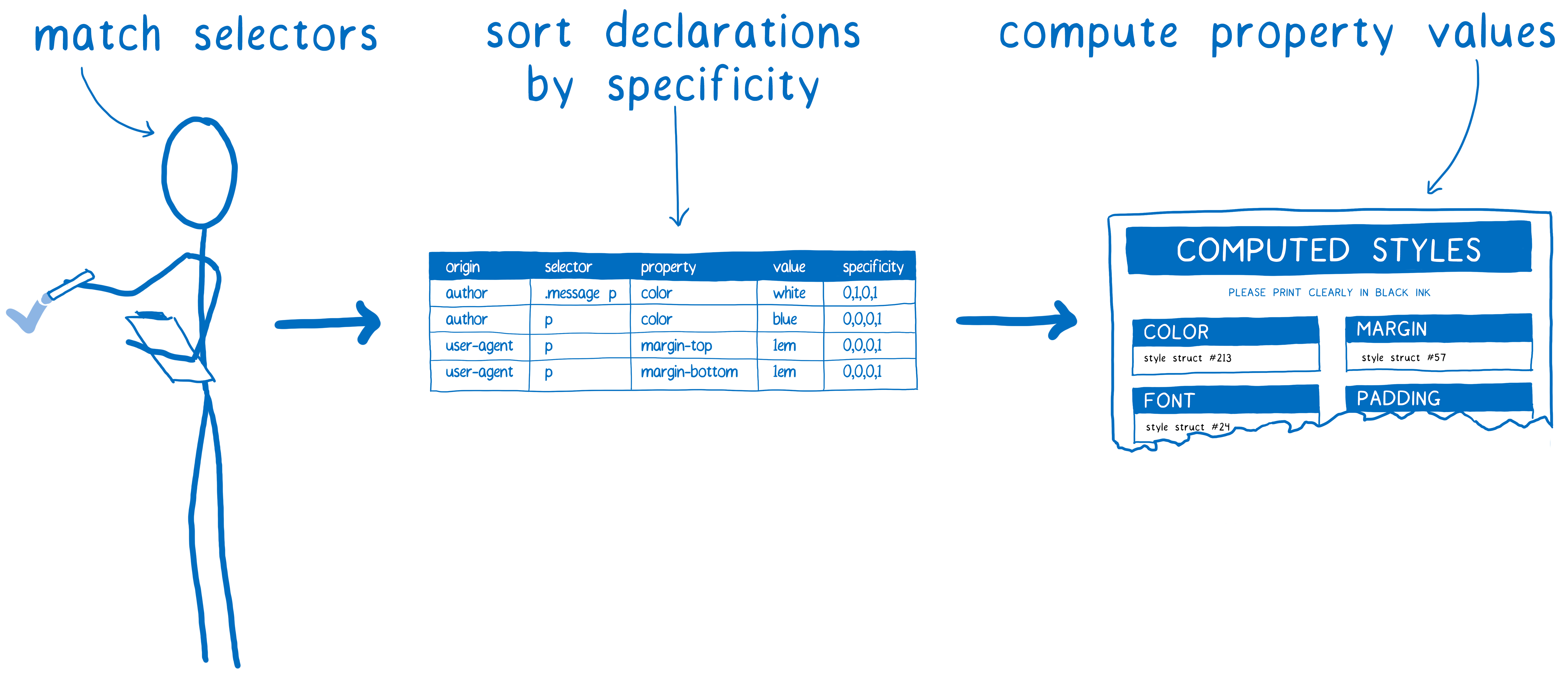
选择器匹配
这一步骤中,把和 DOM 节点匹配的所有规则添加到一个列表。 因为可能匹配到多个规则,所以同一属性就可能出现多个声明。
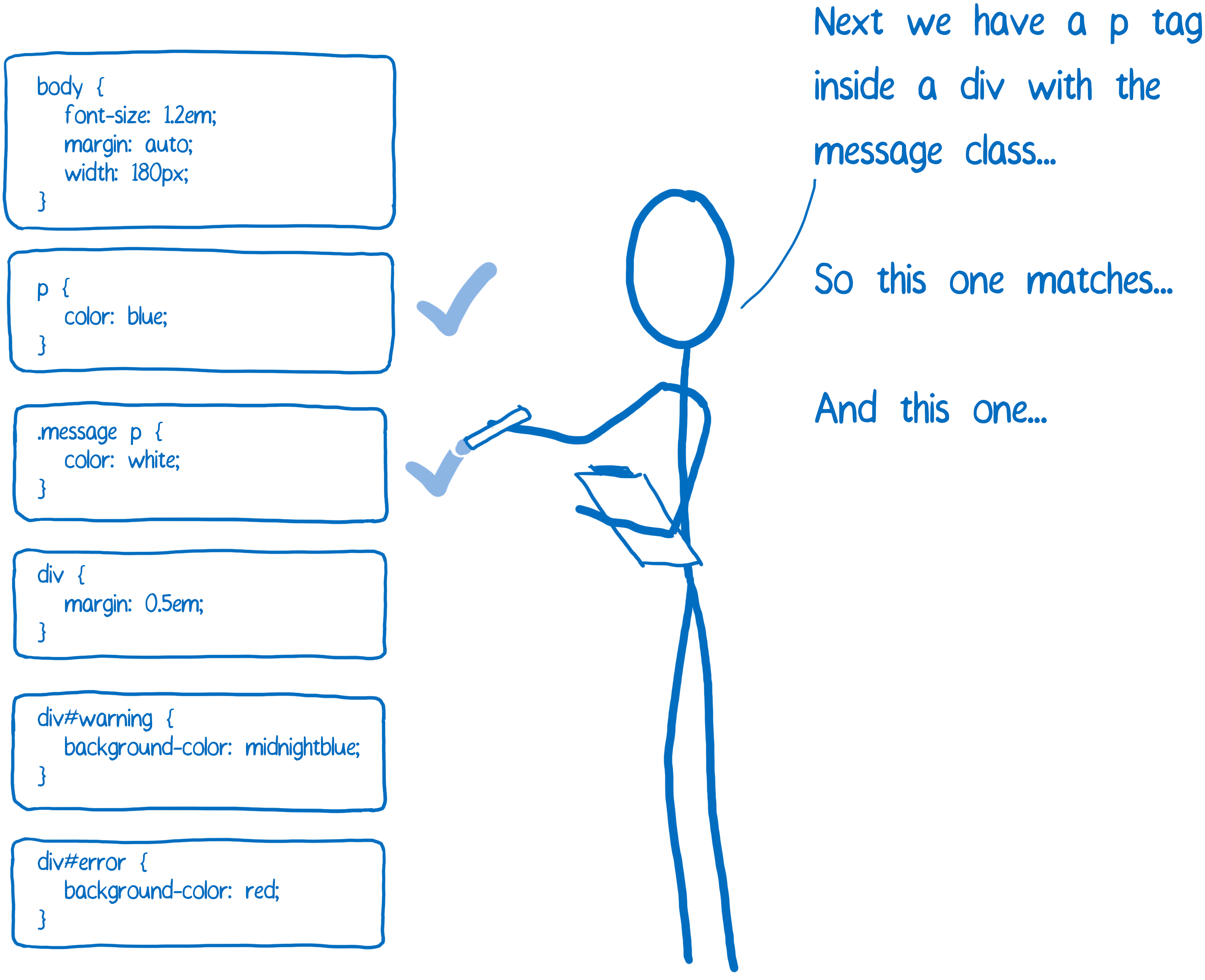
另外,浏览器自身也添加了默认 CSS 规则(用户代理样式表)。 CSS 引擎如何知道应该选择哪个值呢?
这里就有优先级规则出现了。 CSS 引擎创建一个表格。 然后根据不同列对声明做排序。

具有最高优先级的规则胜出。 根据这个表格,CSS 引擎填充已经可以确定的值。

其余的值,则使用层叠。
层叠(cascade)
层叠使 CSS 易于编写和维护。
使用层叠,可以在 body 上设置 color 属性,p 和 span 和 li 中的文本都会使用该颜色(除非有一个更高优先级的覆盖)。
CSS 引擎在表格里查看空白盒子。 如果该属性默认继承,那么 CSS 引擎就沿着树形结构向上,查看祖先节点是否有值。 如果全部祖先节点都没有值,或者该属性不继承,就获得一个默认值。

这时已经为这个 DOM 节点计算了所有样式。
旁注:样式结构体共享
上面看到的表格可能有一点儿误导性。 CSS 有成百上千的属性。 如果 CSS 引擎保持每个 DOM 节点的每个属性值,会很快耗尽内存。
因此,引擎会做 样式结构体共享。
经常在一起的数据(如字体属性)被保存在一个叫做样式结构体的对象里。
不再将全部属性保存在同一对象里,而是让对象只持有指针,指向计算出的样式。
对于每个类别,都有一个指针指向样式结构体,具有此 DOM 节点应有的正确值。
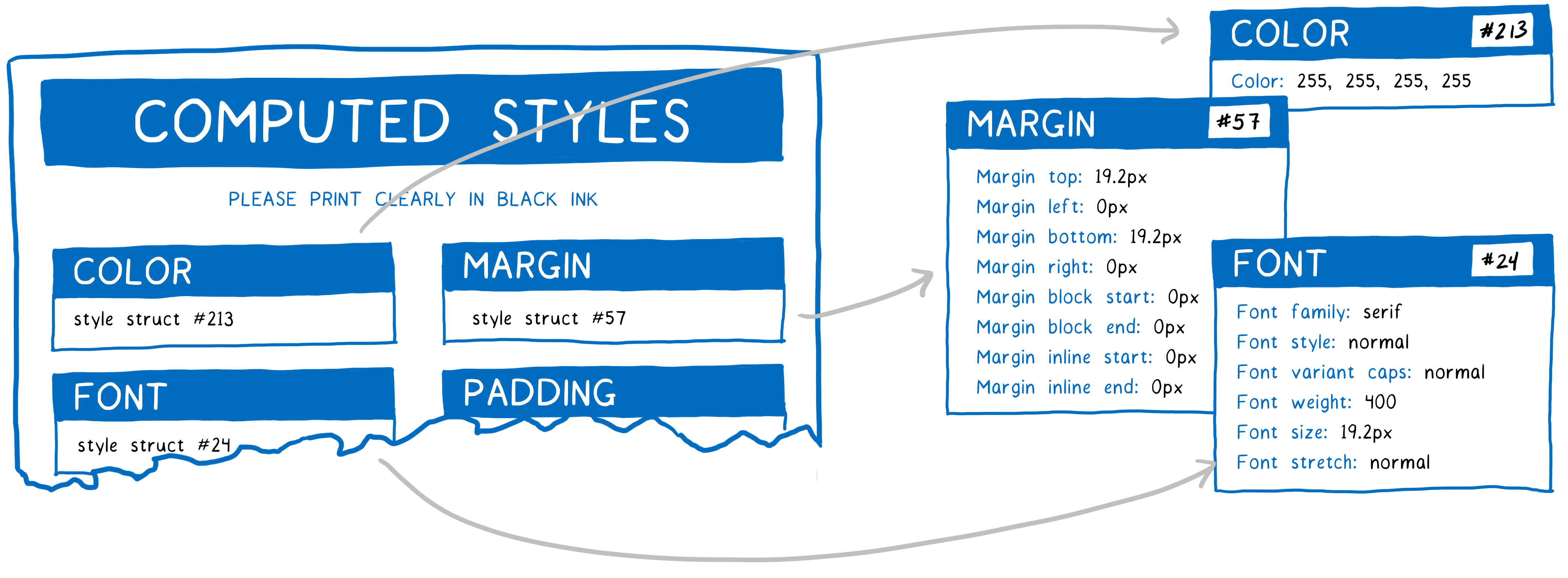
这样节省了内存和时间。 具有相似属性的节点(如兄弟节点)可以把共享的属性指向相同的结构体。 因为很多属性是继承的,如果该后代没有特别指定覆盖的话,祖先节点也可以与后代共享结构体。
现在,如何做到更快?
这是没有优化时,样式计算的样子。
这里发生了很多工作。 不仅第一次页面加载时发生。 当用户与页面交互、鼠标在元素上悬停、或更改 DOM 时,会反复发生,触发样式重建。
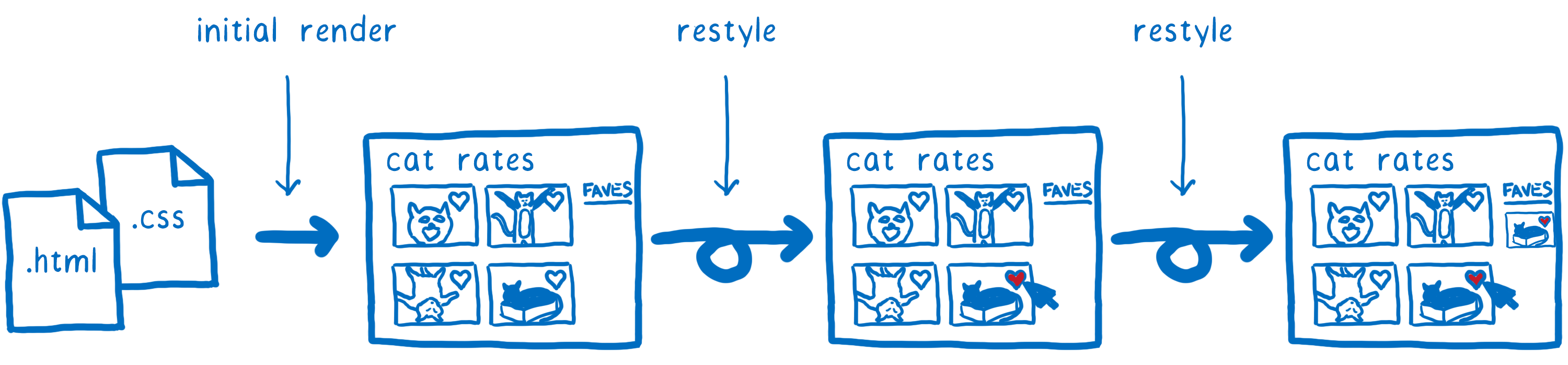
这表明 CSS 样式计算是很好的优化之选…… 过去 20 年里浏览器们一直在测试不同的优化策略。 Quantum CSS 所做的是从不同浏览器引擎中择取最好的策略,并把它们结合起来创造出一个超级快的新引擎。
下面来看看它们如何协同工作的细节。
全都并行运行
Servo 项目(Quantum CSS 来自于此)是一个实验性的浏览器,它试图把网页渲染的所有部分并行化。 这是什么意思呢?
计算机就像大脑。 一部分负责思考(算术逻辑单元/arithmetic logic unit, ALU)。 紧邻着有一些短期记忆体(寄存器)。 它们在 CPU 上组合在一起。 还有更长期的记忆体,RAM(随机存取存储器/Random Access Memory, RAM)。
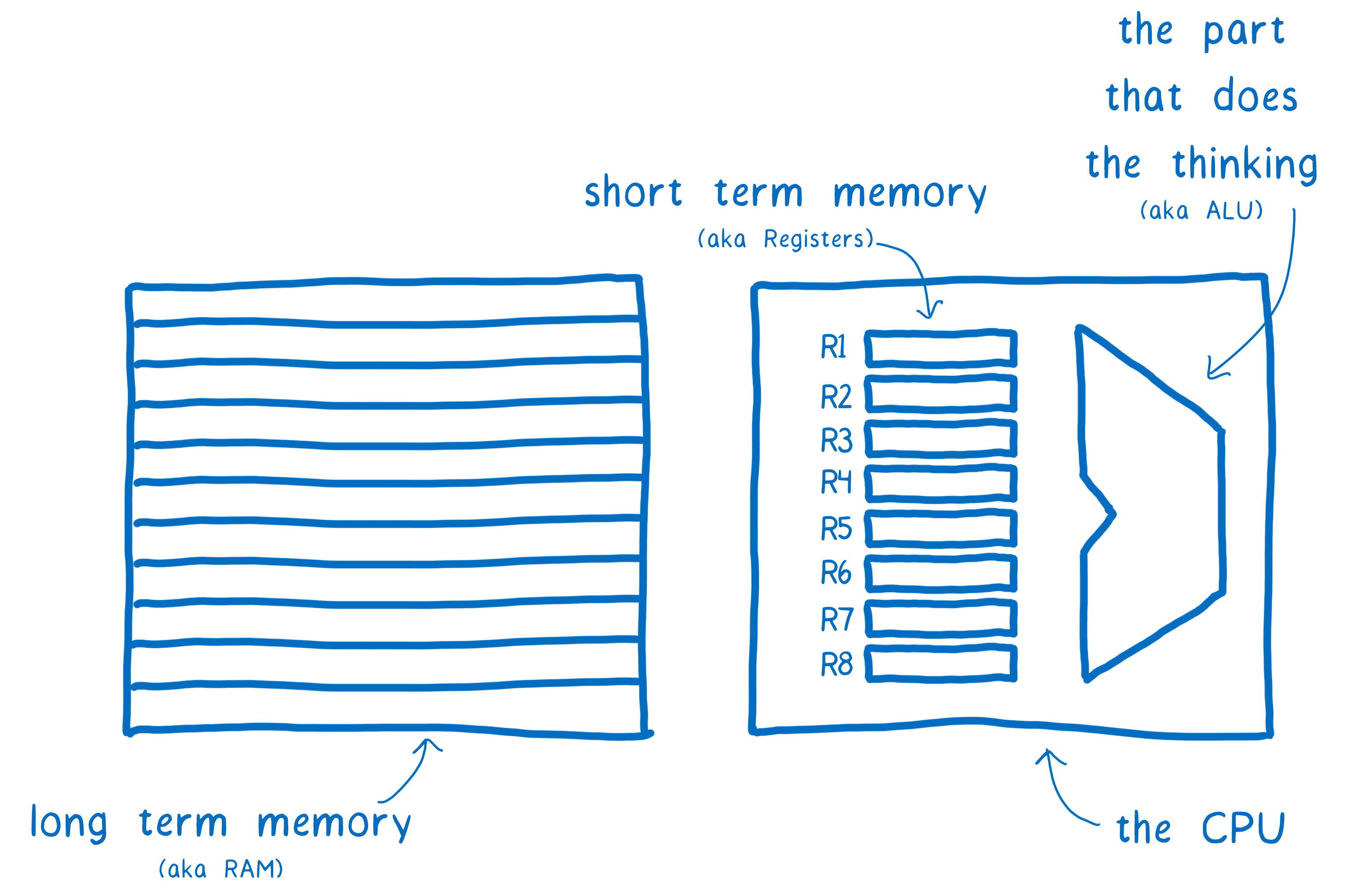
早期的计算机使用这种 CPU 仅能同时思考一件事。 但是过去的十多年里,CPU 变为有多个 ALU 和寄存器,在 CPU 核心上组合在一起。 这样 CPU 可以同时思考几件事——并行。

Quantum CSS 利用这些最新计算机特性,将不同 DOM 节点的样式计算分配给不同核心。
看起来很简单…… 只要把树按分支拆分,在不同核心上运行。 实际上更难一些,原因很多。 其中一个原因是 DOM 树经常是不均匀的。 其中一个核需要比其它核做更多的工作。
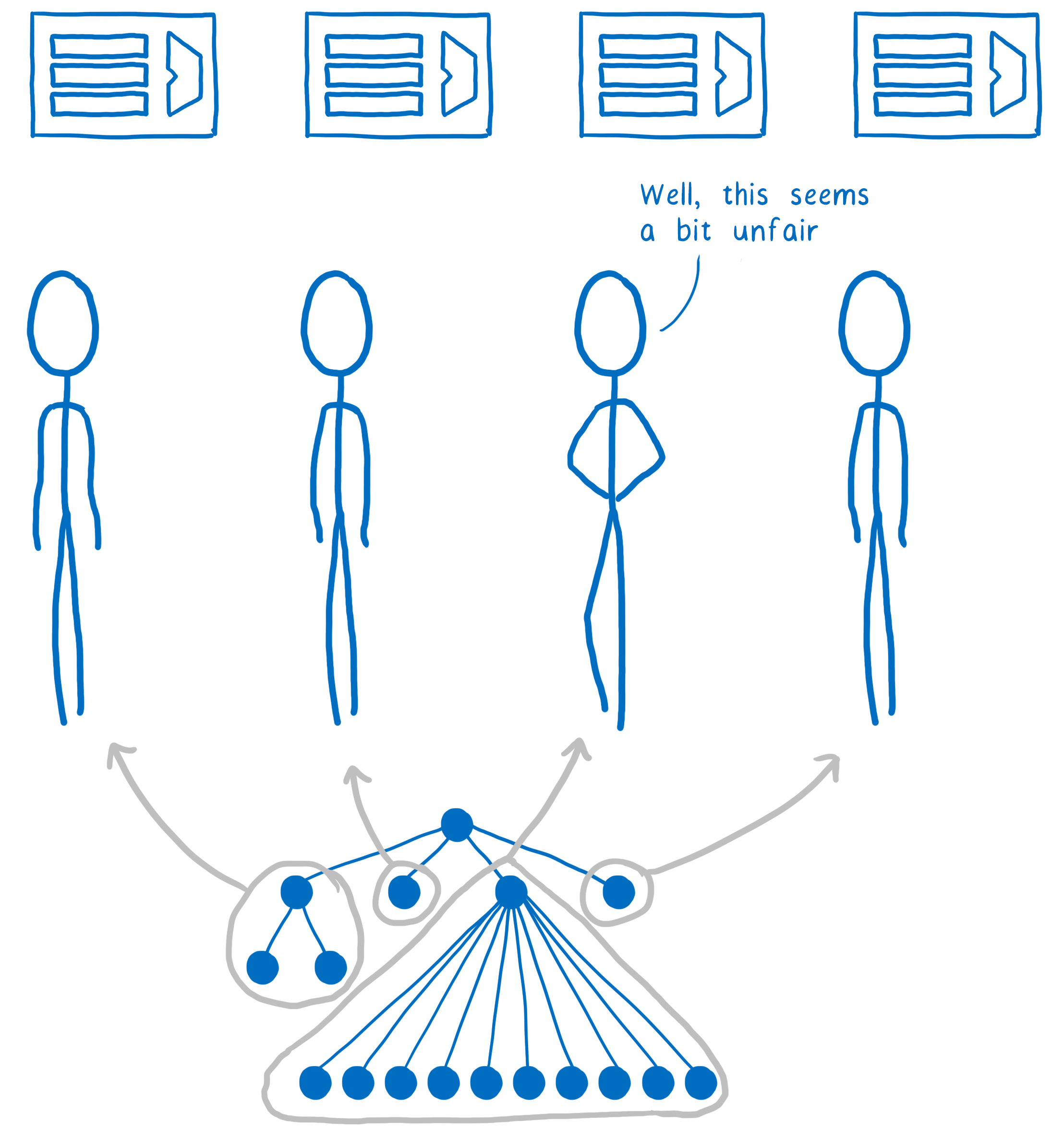
为了平衡工作,Quantum CSS 使用一种叫做工作窃取(work stealing)的技术。 一个 DOM 节点在处理时,代码将它的直属子节点拆分为 1 个或多个“工作单元”。 这些工作单元被放进队列。

当一个核心完成了队列里的工作,它可以在其它队列里获得更多的工作。 意味着我们可以均匀的分配工作,而不需要提前遍历整个树去计算如何平衡。

大多数浏览器里,很难正确实现并行。 并行是已知的难题,CSS 引擎非常复杂。 并且处于渲染引擎中最复杂的两个部分之间——DOM 和布局。 所以很容易产生错误,并行化可能会导致很难追踪的错误,称为数据竞争。 这类错误在另一篇文章中有详细解释。
如果成百上千的工程师都在贡献代码,并行化编程如何能不担心? 这是我们引入 Rust 的目标。

使用 Rust,可以静态验证确认没有数据竞争。 只要一开始不让它们进入代码,就可以避免棘手的调试错误。 编译器不允许你这么做。 这方面未来会写更多文章介绍。 现在,你可以看 intro video about parallelism in Rust 或 more in-depth talk about work stealing。
这样,CSS 样式计算变成了并行问题——没有什么能阻止你高效的并行运行。 也意味着可以获得线性的加速效果。 如果机器有 4 个核心,可以接近以 4 倍速度运行。
用规则树(Rule Tree)加速样式重建(restyle)
每个 DOM 节点,CSS 引擎需要遍历全部规则来进行选择器匹配。 对于大多数节点,匹配不经常变化。 例如,如果用户将鼠标悬停在父节点,它匹配的规则可能会变化。 仍然需要重计算它的后代节点的样式来解决属性继承,但是后代节点匹配的规则可能并没有变化。
所以最好记下哪个规则匹配了这些后代节点,这样就不需要再次对它们做选择器匹配了…… 这就是规则树(借鉴了 Firefox 前一代 CSS 引擎)做的事。
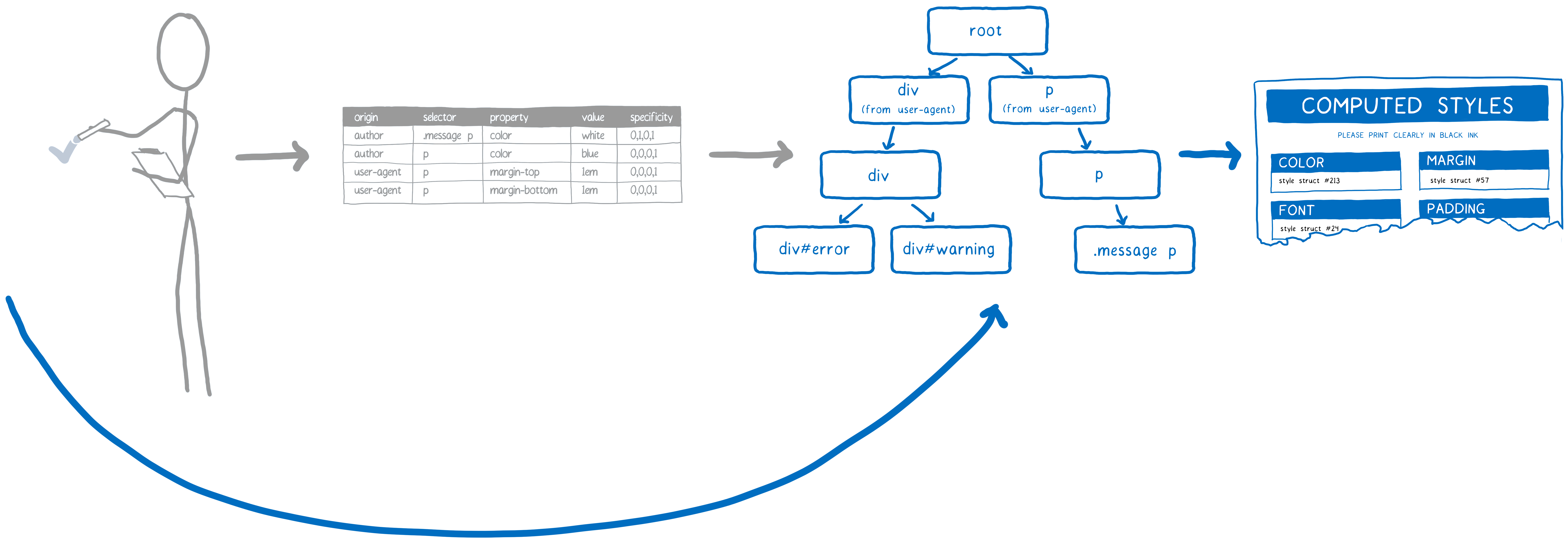
CSS 引擎经过一个过程,找到那些可匹配的选择器,然后对其按照优先级排序。 这时,它就建好了规则链表。
该列表会添加到规则树中。

CSS 引擎尝试将树中的分支数量保持最小。 为此,它将尽可能的复用分支。
如果一个列表中的大多数选择器与已有分支相同,则沿用同样的路径。 但是可能有一个点,列表中的下一个规则不在这个分支上。 只在这一点才添加新分支。
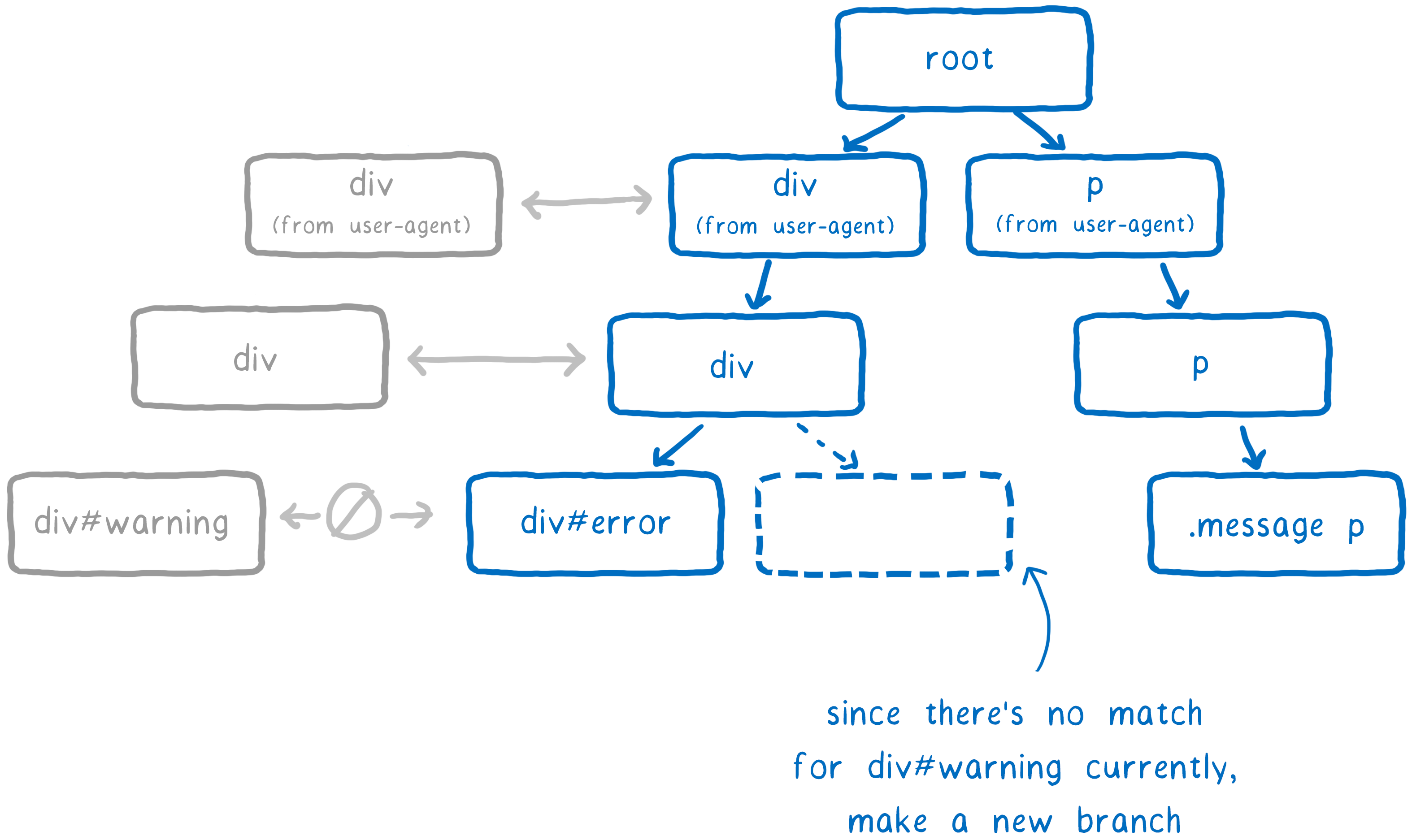
DOM 节点得到一个指针,指向最后添加的规则(本例中,dev#warning 那条规则)。
这是最优先的一条。
样式重建时,引擎先迅速检查父节点的改变是否可能改变子节点匹配的规则。 如果不改变,对于任何后代,引擎可以直接根据后代节点的指针找到那条规则。 从那条规则,它能沿着规则树向上找回根,得到匹配规则的完整列表,从最高优先级到最低优先级。 也就是说可以完全跳过选择器匹配和排序的过程。
这有助于减少样式重建过程的工作量。 但是初始化样式时仍然有很多工作。 如果有 10,000 节点,仍然需要做 10,000 次选择器匹配。 有另一种方法来加速。
使用样式共享缓存(Style Sharing Cache)加速初始渲染(和层叠)
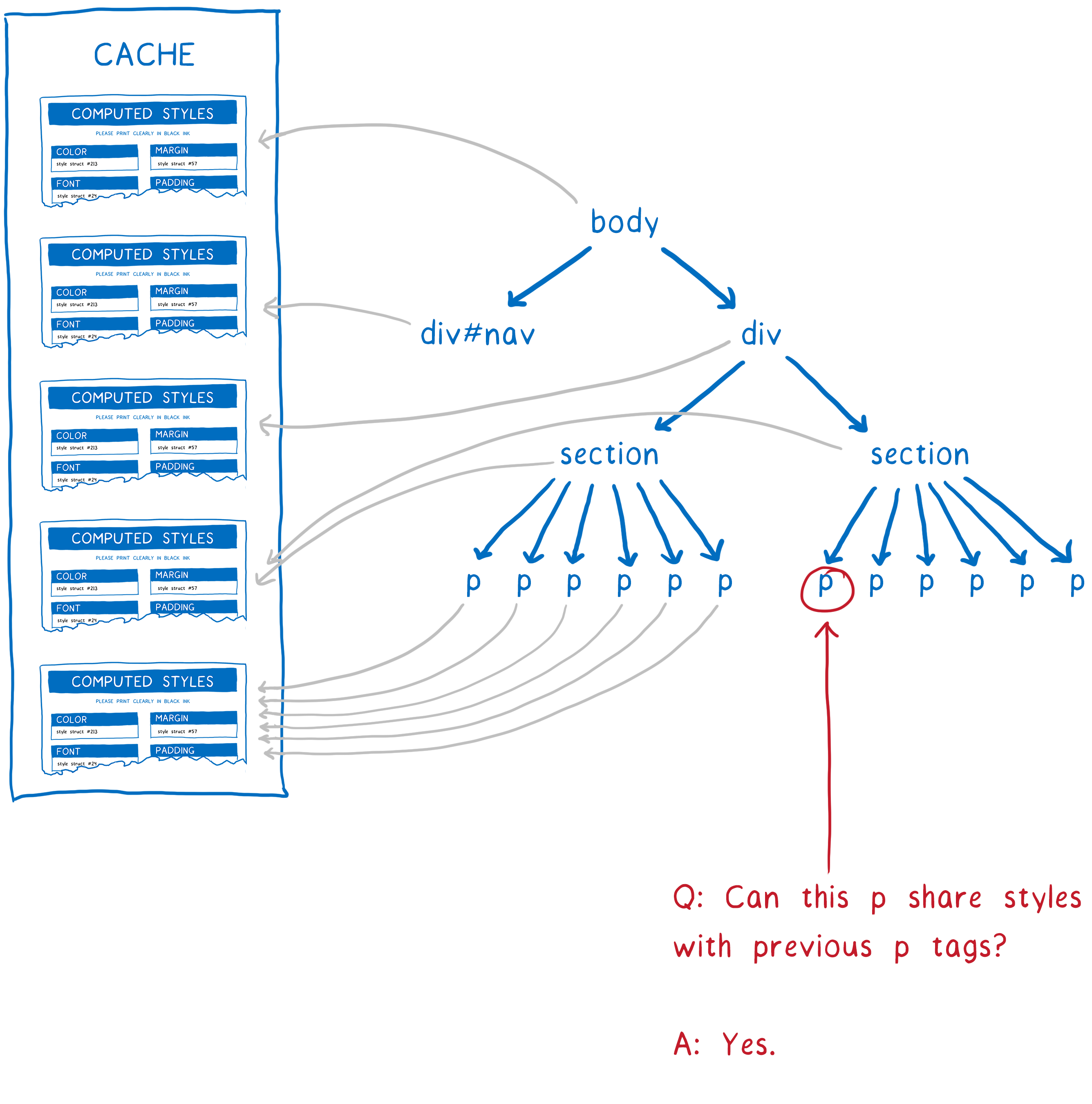
考虑有成千上万个节点的页面。 很多节点匹配相同规则。 例如,一个很长的 Wikipedia 页面…… 主内容区域内的段落最终应该匹配完全相同的规则,具有完全相同的计算样式。
如果不做优化,CSS 引擎必须对每个段落匹配选择器并计算样式。 但是如果有办法证明段落与段落的样式都相同,引擎就可以只做一次工作,把每个段落节点指向同一计算样式。
这就是样式共享缓存(受 Safari 和 Chrome 启发)的做法。 一旦处理完一个节点,就将计算出的样式放入缓存。 然后,在计算下一个节点的样式之前,它会运行几个校验来看是否能使用缓存。
这些校验包括:
- 两个节点是否有相同 id、class 等? 如果有,有可能匹配同一规则。
- 任何不是基于选择器的——如内联样式——节点是否有相同的值? 如果是,以上的规则或者不被覆盖,或者以相同的方式覆盖。
- 两者的父节点指向计算出的同一样式对象? 如果是,继承的值也将相同。
从一开始这些校验就存在于早期的样式共享缓存的实现中。
但是也有很多其它小案例,样式可能匹配不上。
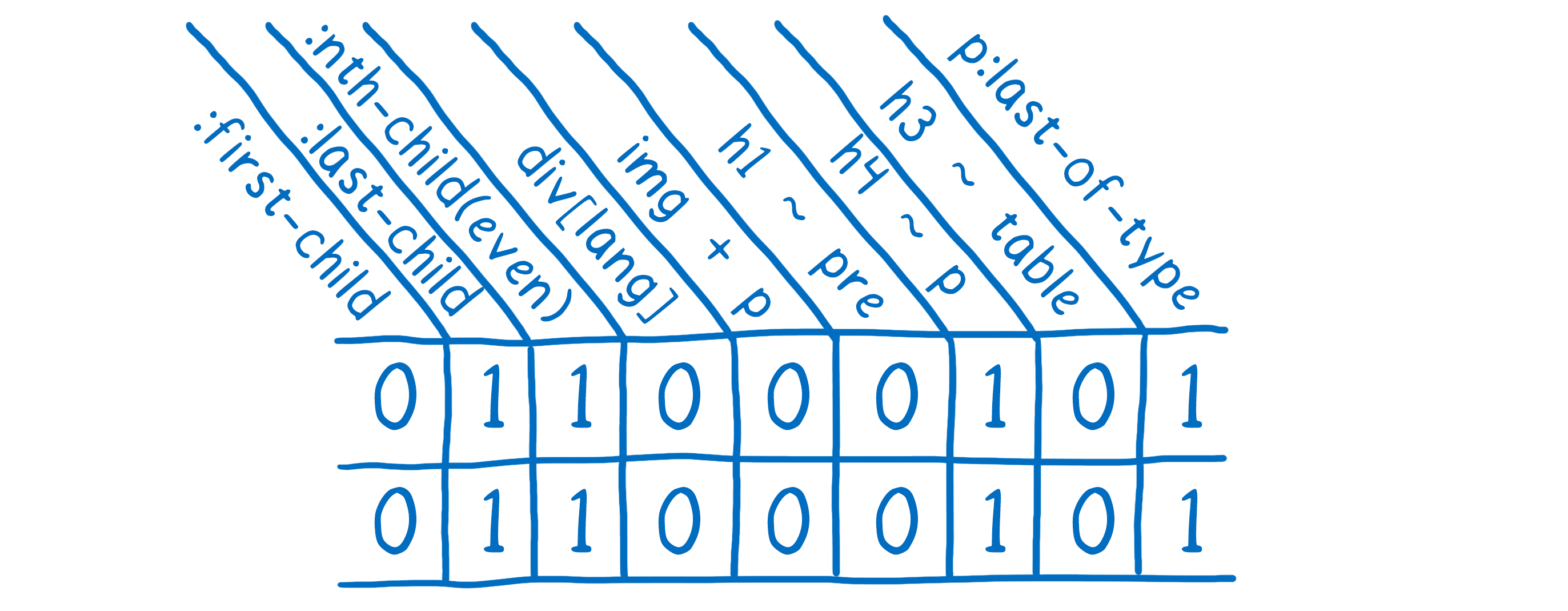
例如,如果 CSS 规则使用 :first-child 选择器,两个段落可能不匹配,即使以上校验表明它们匹配。
在 WebKit 和 Blink 里,样式共享缓存在这种情况下停止,不再使用缓存。 随着越来越多网站使用这些现代的选择器,这一优化变得用途越来越小,所以 Blink 团队最近把它移除了。 但事实上还有一种方法,让样式共享缓存能跟上这些变化。
Quantum CSS 先汇总这些特别的选择器,检查它们是否适用于 DOM 节点。 然后将答案以 1 和 0 的形式存储。 如果两个元素具有相同的 1 和 0,就知道它们绝对匹配。
如果 DOM 节点能共享已经计算过的样式,就可以跳过几乎所有的工作。 因为页面经常有很多 DOM 具有相同样式,样式共享缓存可以节省内存,并真的能加快速度。
结论
这是从 Servo 到 Firefox 的第一个重大技术转移。 关于如何把 Rust 写出的现代化、高性能代码引进 Firefox 主干,一路上我们学到很多。
我们很兴奋,这一个大型的 Quantum 项目已经准备好让用户直接进行体验。 我们很乐意让你们试用,如果发现任何问题请告知。