一次服务器IOPS偏高的追踪过程
最近有同事注意到一台线上服务器的SSD寿命消耗比较快,因此对数据写入情况做了追踪。
现象描述
通过df能明显看到硬盘分区/dev/sda1空间的变化,约10-20s左右会写一批数据,约3GB左右,然后数据被删除。
[root@67-31 conf]# df -h
文件系统 容量 已用 可用 已用%% 挂载点
/dev/sda1 50G 6.4G 41G 14% /
tmpfs 63G 0 63G 0% /dev/shm
/dev/sda3 207G 161G 36G 83% /data
[root@67-31 conf]# df -h
文件系统 容量 已用 可用 已用%% 挂载点
/dev/sda1 50G 3.7G 44G 8% /
tmpfs 63G 0 63G 0% /dev/shm
/dev/sda3 207G 161G 35G 83% /data
[root@67-31 conf]# df -h
文件系统 容量 已用 可用 已用%% 挂载点
/dev/sda1 50G 4.1G 43G 9% /
tmpfs 63G 0 63G 0% /dev/shm
/dev/sda3 207G 162G 35G 83% /data
通过df -i查看inode数量没有明显变化,能确定是操作了一个(或一些)比较大的文件。
[root@67-31 conf]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)%% 挂载点
/dev/sda1 3276800 186694 3090106 6% /
tmpfs 16512042 1 16512041 1% /dev/shm
/dev/sda3 13729792 15806 13713986 1% /data
[root@67-31 conf]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)%% 挂载点
/dev/sda1 3276800 186694 3090106 6% /
tmpfs 16512042 1 16512041 1% /dev/shm
/dev/sda3 13729792 15805 13713987 1% /data
现象确认
首先找出来磁盘IO操作比较多的进程。这次使用的神器是iotop
iotop -d 1 -obk -a | cut -c -200
由于这台服务器上只有redis服务和一些java程序,java程序的process name比较长,所以cut一下。
从输出来看,大部分输出是redis-server这个进程产生的。可以确定是redis-server这个进程造成。
继续用iotop检查redis的操作规律:
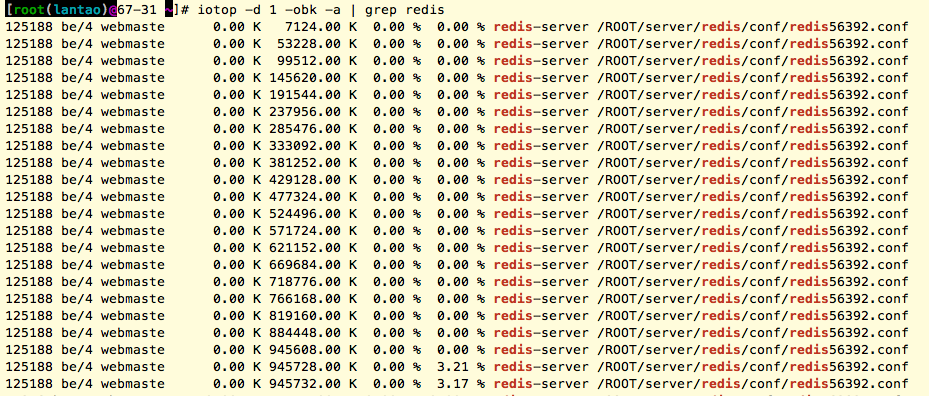
通过redis-server的pid可以看到改进程正在操作的文件名:
ls -l /proc/<pid>/fd/
看到该进程操作的文件名为/home/redis/temp-123134.rdb
到目前为止,我们找到了有问题的进程名和涉及的文件,似乎现象已经清楚了。下面开始查找原因。
追查原因
Redis是一个数据存储/缓存软件。
类似软件总有各种磁盘操作的问题。 出于性能考虑,这类软件的数据大都在内存中缓存,然后同步到磁盘上,如果选择的同步策略与应用场景不匹配,就会出现问题。
先看一下redis的配置
...
timeout 0
databases 16
save 60 10000
rdbcompression yes
dbfilename /data/redisdb/dump-56392.rdb
dir ./
slave-serve-stale-data yes
maxclients 500
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
slowlog-log-slower-than -1
slowlog-max-len 1
vm-enabled no
vm-swap-file /tmp/redis.swap
vm-max-memory 0
vm-page-size 32
vm-pages 134217728
vm-max-threads 4
maxmemory 16294967296
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
...
注意其中关于save的配置:
# Save the DB on disk:
#
# save <seconds> <changes>
#
# Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
#
# Note: you can disable saving at all commenting all the "save" lines.
save 60 10000
这个参数可能在更新比较频繁时,能导致数据频繁写入文件系统。直觉告诉我,这个可能性超过60%。
从
Redis邮件组里的一个讨论可以看到类似关于Redis的SAVE和BGSAVE过程的探讨。
那数据更新发生的频率到底怎样呢?
# while true; do date; ./redis-cli -h 127.0.0.1 -p 56392 info | grep total_commands_processed; sleep 10; done
Fri Feb 28 11:51:22 CST 2014
total_commands_processed:401363929
Fri Feb 28 11:52:22 CST 2014
total_commands_processed:401371925
估算出每分钟有七千多次操作,注意这个操作数包含读和写,纯写入操作的数据应该很少。
因此save发生的周期至少是60秒+10000次更新操作的时间,估算肯定超过2分钟。
与之前观察到的现象有出入。这条线索似乎到此已经断了。
从配置文件往下看:
dir ./
想到刚才查出的那个大文件,正好在dir指定的这个目录。
继续往下看:
dbfilename /data/redisdb/dump-56392.rdb
数据文件保存到了另一个单独的数据分区里。
从这两点可以推测发生了文件的跨分区转移。 不过从之前的现象来看/data所在分区/dev/sda3的磁盘操作很少。
现在来回头看看redis的日志。有一行内容值得怀疑:
Error moving temp DB file on the final destination: Invalid cross-device link
这条失败记录非常重要,确认发生了跨设备的文件操作,而且解释了/dev/sda3磁盘操作很少的现象。
看到这里,可以进行再一次推演:
- 数据更新数量(changes)达到save参数指定的10000个,触发save流程
- 60秒后开始写temp文件(即刚才看到的大文件);
- 约20秒后写完temp文件;
- 开始rename。但是源与目标不属于同一个设备,所以失败
- 整个save流程失败!
- 内部计数器保留的changes保持不变
- 由于redis内存数据与磁盘数据差异仍然超过10000个,即使最近60秒没有新的change,仍然要立即重新进行上一步骤。
- 重试结果持续失败,从长期趋势来看,形成每20秒为周期的高IOPS现象。
这一假设能够符合刚才观察到的所有现象,最终的原因是以下两方面组合造成:
- 开启了
save dbfilename与dir在不同设备,save失败
阻断任何一个都可消除IOPS过高的现象。
补充:
实际使用Redis过程中,开启save导致iops过高比较常见,需要多关注。
至于temp文件与dbfile在不同设备的情况比较少见。